Untangling disagreements about the possibility of AI scientists
Search, possibility and probability

At a self-driving labs event hosted by ARIA and SoTA there was a lively disagreement between Lee Cronin of Chemify and the ARIA-funded AI scientist teams. Lee raised philosophical objections to the possibility of AI scientists, claiming that they cannot conjecture hypotheses and that science cannot be reduced to search.
There wasn’t time for a proper debate at the event, so I’ve tried to steelman Lee’s argument, which I believe centres around search, possibility, and probability. I think Lee is arguing from a Deutschian perspective and have interpreted his claims through that lens - but I’m no expert on the philosophy of science, so corrections are welcome.
Search and Learning
One point that Lee made during the event was that the space of chemical reactions is too large to search, and that search alone is not enough to create an AI scientist.

Let’s compare the search space of chess to chemical reaction space. In chess, each turn you have a choice of around 38 moves on average. For every one of those, your opponent has ~38 responses. This gives a game tree with a branching factor of 38 and roughly 10^40 legal game states which is more than the number of stars in the observable universe.
Chess-playing AI engines overcome this by using a trained approximator (eg. a neural network) to recognise patterns similar to what they saw during training, combined with multi-step lookahead search to correct for the data distribution shift that arises from never having seen the exact position before. It's very unlikely you'll play the same chess game twice, but the trained approximator is still useful because chess games share recurring structural features (forks, pins, open files, king safety patterns) that generalise across games.
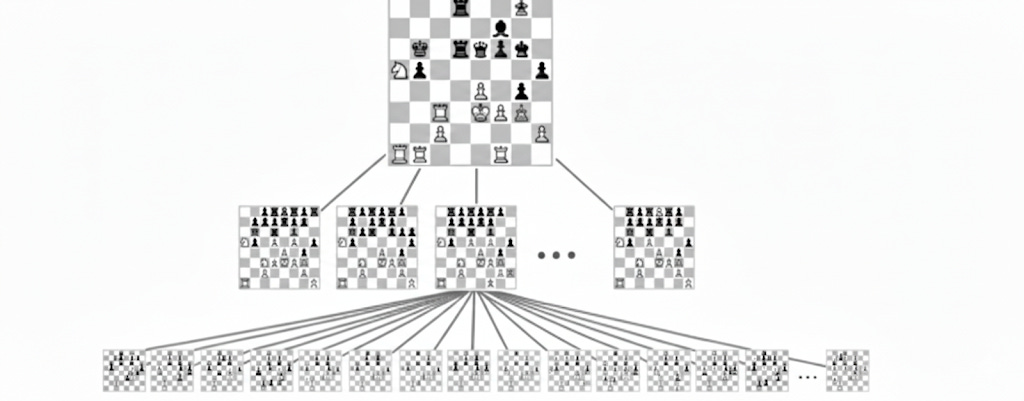
Chemistry has a far larger search space. The “board” is all possible molecules; the “moves” are reactions that transform one into another. Even a small number of starting materials produces an enormous combinatorial explosion: 18 reagents yield ~1,000 possible reaction combinations; allow multi-step synthesis with varying conditions and that number quickly exceeds 10 billion from fewer than a dozen inputs. And this is still tiny - the space of all possible molecules up to 30 atoms using just carbon, oxygen, nitrogen, and sulphur is estimated at 10^60.
Lee’s group has published extensively on using search algorithms to prune down the enormous chemical search space.1234567 So in this respect Lee is clearly not anti-search, in fact his approach of scaling autonomous chemistry labs and performing high throughput search appears consistent with the mainstream “bitter lesson-pilled” view of search and scaling in AI.

So why shouldn’t Lee be excited about scaling search and learning to achieve superhuman AI chemists the same way we achieved superhuman AI chess players? After all, both chess and chemistry have search spaces too large to enumerate, but also learnable structures and regularities that an AI can exploit to guide its search efficiently. Shouldn't we expect the same approach to work for chemistry?
I found the clearest articulation of the Cronin Group's objection in this article from Lee’s collaborator Sara Walker.
Chemical space cannot be computed, nor can the full space be experimentally explored, making probability assignments across all molecules not only impossible but unphysical; there will always be structure outside our models which could be a source for novelty. - Why the Physics Underlying Life is Fundamental and Computation is Not by Sara Walker
Sara’s argument is that chemistry has an open-endedness that chess does not - new molecules can create new conditions (catalysts, environments, physical contexts) that enable reactions that were impossible before those molecules existed. A novel catalyst could open up a region of reaction space that has no structural similarity to anything in the training data, because it didn’t exist as a possibility before.
Imagine a variant of chess where pieces that reach certain configurations can combine to create entirely new piece types with movement rules that didn’t exist at the start of the game. Your neural network might still handle the opening - but mid-game, players start producing pieces it’s never seen, with abilities that couldn’t have been predicted from the starting rules. You can’t assign a probability to a threat from a piece type that doesn’t exist yet.
The Walker/Cronin claim, as I understand it, is an argument about the difference between probability and possibility. A probabilistic model assigns likelihoods over a space defined by what it's seen - it can interpolate within that space and extrapolate along familiar dimensions - but it can't represent possibilities that don't yet exist in any form in its training data. And for Lee and Sara, it's precisely those new possibilities that constitute true scientific discoveries.
Possibility and Probability
If the open-endedness of chemical space is a constraint on every agent navigating it, what is it that human scientists supposedly do that an AI can’t? From Lee’s tweets, I get the sense that his answer is: to make genuine discoveries, you need to be able to imagine completely new possibilities - to invent a possible world, not just search within the existing one.
On the surface, LLMs can already do this - you can easily get them to propose hypotheses, design experiments, and analyse results autonomously. But Lee’s deeper claim, I think, is that truly creative hypothesis generation requires reasoning over logically possible worlds, not merely probable ones.
To create a chess-playing AI engine, humans provide the rules of chess and the model teaches itself to play at a superhuman level through self-play. But we’d never expect it to invent anything outside the sandbox universe we created for it. It can’t propose a new game, or suggest a rule change to make chess more interesting. It is, in Popper’s terms, an induction machine:
…we may consider the idea of building an induction machine. Placed in a simplified “world” such a machine may through repetition “learn”, or even “formulate”, laws of succession which hold in its “world”… In constructing an induction machine we, the architects of the machine, must decide a priori what constitutes its “world”; what things are to be taken as similar or equal; and what kind of “laws” we wish the machine to be able to “discover” in its “world”. In other words we must build into the machine a framework determining what is relevant or interesting in its world: the machine will have its “inborn” selection principles. The problems of similarity will have been solved for it by its makers who thus have interpreted the “world” for the machine. - Conjectures and Refutations by Karl Popper
The real question for AI science is whether the same constraint applies to frontier language models. After all, their “world” and “inborn selection principles” are much more general, having been pre-trained on essentially the sum of human declarative knowledge. Are they ultimately bounded by those inborn facts and rules, or are they capable of imagining possible worlds beyond them?
Consider Demis Hassabis’ “Einstein test”: train a foundation model with a knowledge cutoff at 1911 and see if it could produce general relativity. A model trained on pre-1911 data would have learned that Newtonian mechanics was one of the most successful theories in history. Every well-designed experiment had corroborated it. A probabilistic reasoner would have assigned near-certainty to Newton being correct. It wasn’t until 1919, when Eddington measured starlight bending near the sun at roughly double the Newtonian prediction, that Einstein’s theory was accepted - despite directly contradicting centuries of established mechanics.
The real paradox is that Newtonian mechanics was shown to be false at precisely the point when a probabilistic model would have been most confident it was true. New scientific theories are, almost by definition, improbable or even absurd by the standards of incumbent theories.
Beren Millidge makes the general version of this argument in machine learning terms:
The reason scaling pretraining (aka unsupervised learning on a fixed corpus of e.g. web data) does not scale to AGI or imply omniscience is pretty simple. The object that pretraining optimizes is the approximation to the true posterior over token sequences taken from the internet. Better scaling means better approximating the distribution of common-crawl. The distribution of common-crawl does not contain superintelligent behaviour and hence scaling alone will not reach it… To see this more clearly, let’s go back to the example of prompting the pretrained model with ‘The solution to alignment is: ‘. Suppose the model somehow magically generalized deeply and actually knew the solution to alignment. Even if this was the case, actually completing this prompt with the solution to alignment would be incredibly unlikely for the model…. - The Limit of Prediction is not Omniscience by Beren Millidge
Even if a model somehow "knew" a revolutionary new theory, producing it would be incredibly unlikely under a distribution trained on a world where that theory doesn't yet exist. That, I think, is what Lee is getting at by pointing at the asymmetry between probability and possibility: probability tells you what's likely within a known world, only possibility can allow you to invent a new one.
I’ve tried to steelman Lee’s argument, and I think it raises genuine philosophical questions that the AI scientist teams haven’t fully grappled with: can a system trained on existing knowledge propose possibilities that lie outside of its inborn facts and rules, or is it fundamentally limited to recombining what it’s already seen? I don’t know the answer. Whether this philosophical distinction has practical consequences, or whether it describes a limit that engineering will route around, remains to be seen. My view nowadays is that I’ve been humbled (or “bitter lessoned”) over and over again by asserting on lofty philosophical grounds that scaled search and learning won’t smash through whatever capability we set beyond the reach of AI models, but I still find the arguments and paradoxes interesting. I'd love to be a part of a more structured debate between Lee and a representative from the AI scientist teams to explore these disagreements further.
Caramelli et al., *ACS Cent. Sci.* 7, 1821–1830 (2021). [doi:10.1021/acscentsci.1c00435](https://pubs.acs.org/doi/10.1021/acscentsci.1c00435). CNN trained on 440 reactions, transferred to 1,018 in a different space; found novel photochemical reaction and trimeric cascade product (5 new C–C bonds, 47% yield).
Mehr, Caramelli & Cronin, *PNAS* 120, e2220045120 (2023). [doi:10.1073/pnas.2220045120](https://www.pnas.org/doi/10.1073/pnas.2220045120). Autonomously rediscovered 8 named reactions (Aldol, Suzuki, Heck, Wittig, etc.) from >500 robotic experiments.
Grizou et al., *Sci. Adv.* 6, eaay4237 (2020). [PubMed:32064348](https://pubmed.ncbi.nlm.nih.gov/32064348/). Curiosity algorithm from Oudeyer/Kaplan developmental robotics. 10× more behavioral variety than random search; discovered unexpected temperature-dependent droplet response.
Parrilla-Gutierrez et al., *Nat. Comms.* 5, 5571 (2014) and *Nat. Comms.* 8, 1144 (2017). Standard GA evolved oil droplet protocells for locomotion, division, vibration. 2017 paper showed open-ended evolution beyond initial fitness landscape.
Salley et al., *Nat. Comms.* 11, 2771 (2020). [doi:10.1038/s41467-020-16501-4](https://www.nature.com/articles/s41467-020-16501-4). Physical nanoparticle seeds transferred between generations — embodied Lamarckian/Darwinian hybrid.
Duros et al., *Angew. Chem.* 129, 10955–10960 (2017). [PMC5577512](https://pmc.ncbi.nlm.nih.gov/articles/PMC5577512/). Robot covered ~9× more space than random, ~6× more than humans; 82.4% vs 77.1% prediction accuracy.
Duros et al., *JCIM* 59, 2664–2671 (2019). [PMC6593393](https://pmc.ncbi.nlm.nih.gov/articles/PMC6593393/). Hybrid 75.6% vs algorithm-only 71.8% vs human-only 66.3% — chemistry hasn’t yet fully entered the Suttonian scaling regime.
Thanks for this James, I didn’t understand what Lee was talking about but this makes sense. Trash in = trash out. Good data in = good predictions. Superhuman intelligence in = superhuman intelligence out - we don’t have this last one.