Zero to o1
A concise tour through the history of advances in machine reasoning

Welcome! The purpose of this article is to provide a concise and accessible guide to the history of AI in games like chess and Go, focusing on the ideas that contributed to OpenAI's most recent advancements in language model reasoning. Along the way we will develop a vocabulary of concepts that I'll refer to in my next article, Centaur Era Starts Now, which explores the implications of these advances. If you enjoy this article, consider subscribing to get notified when it’s published.
Here’s a three minute summary of the article if you want a quick overview:
The Drosophila of AI Research
Once upon a time, chess was the frontier of AI research. With its static set of explicit facts and rules, it provided the ideal laboratory environment in which to study problem solving and creativity.
Although perhaps of no practical importance, the question is of theoretical interest, and it is hoped that a satisfactory solution of this problem will act as a wedge in attacking other problems of a similar nature and of greater significance. - Programming a Computer for Playing Chess by Claude Shannon (1949)
Chess is one of the simplest games where in order to pick a good move, players must use strategies more sophisticated than a simple comparison of all possible moves. To understand why, start by thinking about the simpler game of noughts and crosses. With a 3x3 grid, you have a choice of 9 initial moves, and each turn the number of possible legal moves decreases as more of the grid is filled up.

To code an AI noughts and crosses player that performs optimally, it's sufficient to use an exhaustive brute-force search. Each move, recursively simulate playing every possible move and your opponent's responses until you find a line of play that will either lead to a win, or if that’s not possible, a draw. This is feasible because there are at most 362,880 total possible noughts and crosses games.1 While this might seem like a lot to a human, any modern computer would be easily capable of calculating this to see to the end of all lines of play and find the next best move in any grid state.
But problems arise when we try do the same thing in chess - each turn you have a choice of around 38 moves on average. Then for every one of those moves, your opponent will have on average 38 responses to choose from. This results in a game tree with a branching factor of 38 and creates a combinatorial explosion in the number of possible games.
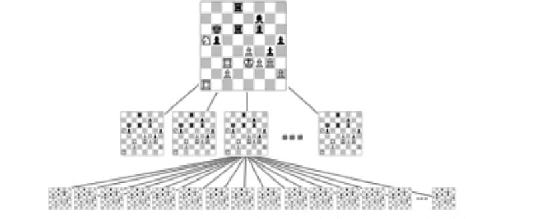
A typical chess game takes about 42 moves, and because there are two players, this is multiplied by two, giving roughly 38^84 (38 to the power of 84) possible choices for a single game. Even after illegal moves are excluded you are still left with roughly 10^40 possible moves, which is more than the number of stars in the observable universe, far too many game states for a computer to reasonably compute.
Therefore the branching factor is a significant contributor to a game's complexity and shares an important relationship to the level of intelligence a game requires. As the complexity rises, players are forced to develop creative problem-solving techniques to help them find good moves without just comparing all possible moves.
The game of chess is therefore an endless open-ended search to find ever-more creative ways to overcome the computational limits of the brain, which makes it extremely addictive for intelligent young minds.
The passion for playing chess is one of the most unaccountable in the world. It slaps the theory of natural selection in the face. It is the most absorbing of occupations. The least satisfying of desires. A nameless excrescence upon life. It annihilates a man. You have, let us say, a promising politician, a rising artist that you wish to destroy. Dagger or bomb are archaic and unreliable - but teach him, inoculate him with chess. - H.G. Wells in Concerning Chess
Players express their creativity through the reasoning shortcuts - intuitions, sixth senses, so-called "heuristics" they hone over years of play. Heuristics are what the psychologists Khaneman and Tversky called "fast thinking", in contrast to manual search which can be thought of as "slow thinking".
So the first step for AI researchers was to turn these human-discovered heuristics into code, then have the computer assign values to potential moves and prune the branches of the game tree down to the most promising options.

As an example of how this was implemented, IBM's chess engine DeepBlue had access to a human-curated database of moves for its "opening-book" - the moves used in the initial stages of a game. It also contained a grandmaster game database of 700,000 games to help it evaluate potential moves. Since chess games are often annotated with “!” to mark strong moves and "?" to mark weak moves, DeepBlue was also able to assign bonuses (or penalties) to such moves in its evaluation function.2
But it's important to note that knowledge alone is not enough to perform well at a game like chess. Since the number of possible chess games is so vast, it's very unlikely that a player will ever see the same game twice, so it's impossible to be completely prepared in advance. Some amount of search will always be useful in allowing you to apply your general knowledge to board states you’ve never seen before.
In fact, DeepBlue actually heavily favoured search over knowledge. Remember that IBM was first and foremost a hardware company, so they built complicated custom parallel processors to power DeepBlue's search system. During its match with the world champion Garry Kasparov, the system was able to evaluate an average of 126 million chess positions per second! Surprisingly, even without revolutionary improvements in its heuristic knowledge, increases in the processing speeds of computers were enough to increase DeepBlue’s performance to the point where it was able to beat Garry Kasparov in 1997.
That’s an extremely important lesson worth highlighting. While relying on search might seem like a less intelligent approach than building up DeepBlue’s store of human knowledge, time and time again through the history of AI “breakthrough progress eventually arrives by an opposing approach based on scaling computation by search and learning.”
In computer chess, the methods that defeated the world champion, Kasparov, in 1997, were based on massive, deep search. At the time, this was looked upon with dismay by the majority of computer-chess researchers who had pursued methods that leveraged human understanding of the special structure of chess. When a simpler, search-based approach with special hardware and software proved vastly more effective, these human-knowledge-based chess researchers were not good losers. They said that “brute force" search may have won this time, but it was not a general strategy, and anyway it was not how people played chess. These researchers wanted methods based on human input to win and were disappointed when they did not. - The Bitter Lesson by Rich Sutton
Intelligence from Thin Air
After the defeat of Kasparov, researchers turned their attention to a new game called Go. Go is a further step up in complexity, with a board size of 19x19 and a branching factor of 361 (compared to 38 for chess). So while chess has more board positions than stars in the observable universe, Go has more positions than atoms in the observable universe!
Go masters are therefore forced to rely even more heavily on fuzzy heuristics and intuitions as opposed to raw calculation in evaluating potential moves.

Because Go masters' intuitions were so hard to formalise into a hand-crafted evaluation function in the style of DeepBlue, it took until the 2010s with the "deep learning" revolution for AI to finally have a shot at competing with the top Go players.
Deep learning is what allowed machines to capture these fuzzy, inexplicit heuristics into a densely connected web of knowledge called a neural net. By asking the network to predict the next best moves in the positions stored in a big database of expert Go games, the network was slowly tuned over time to improve its predictions and approximate the intuitions of an expert human player.
The essence of intuition is the ability to abstract away unimportant details and see the similarities between different scenarios. In noughts and crosses, a simple way we do this is by recognising that rotations and reflections of positions make them effectively the same. So while the total number of possible positions in noughts and crosses is around 5,478, there are only really 765 positions that are different after taking board state symmetries into account.
In Go, learning this kind of fuzzy pattern recognition enables the computer to create its own understanding of high-level concepts Go players use to describe the game, like "life-and-death", "influence" and "territory". Capturing these notions into neural nets allows the AI to see through the fog of war created by the combinatorial complexity of the game tree. Combined with search, the AI can produce reasonable moves in board positions it could never have experienced before.
DeepMind's first attempt at an AI Go player, AlphaGo, was similar to IBM's DeepBlue in that it was bootstrapped with human knowledge through a large database of expert Go games. But after this, the system gathered additional "experience" using a technique called self-play, a kind of reinforcement learning where the model played against itself and used the result of each game (win or loss) to determine which sequences of moves led to winning outcomes. The fact that it was able to train itself autonomously through this process was a very significant departure from the chess and Go engines of the past. It meant that the network was able to go beyond human-discovered knowledge and create completely new ideas of its own.
This was demonstrated in dramatic style in 2016, when AlphaGo defeated the Go world champion Lee Sedol. Both Lee as well as the Go community were shocked at the creativity displayed by AlphaGo, especially in move 37 of game 2 of the match. This move, which commentators originally thought to be a mistake, not only led to AlphaGo winning the match, but has since transformed the way human players see the game.
But the defeat of Lee Sedol was just the start of what makes AlphaGo so important in the history of machine reasoning. Like the defeat of Kasparov in 1997, it was yet more proof that machines could compete with human reasoning, but AlphaGo was still dependent in the early stages on a human-curated database of games. The next logical step was to remove this dependency and have the AI learn completely through self-play. And so AlphaGo Zero was born, zero meaning “zero human knowledge”.
During training AlphaGo Zero used randomised tree searches to explore potential moves. The fact that it was random is very important - firstly, it meant that it abandoned human prior knowledge, relying purely on trial and error instead. Secondly, as you might expect, random search involves much more failure than success - there are only a tiny percentage of good moves in a given position compared to bad ones, so these random searches were computationally expensive. But since there is a very clear feedback signal in the form of wins and losses, the network is able to get better and better at predicting good moves over time. It bakes the knowledge about the good moves it finds back into the network allowing it to directly guess the output of the tree search in the future without paying the computational cost.
It seems so counterintuitive, but this evolutionary approach of abandoning any pre-conceived good ideas about how to play Go and using random search as a teacher instead turns out to produce a superhuman Go player!

AlphaGo Zero is easily able to beat the original version of AlphaGo that defeated Lee Sedol in just three days of training and achieves superhuman levels of performance after training for 21 days.
Just like with chess, it's important to stress that knowledge alone is not enough to reach full performance. The following graph shows the Go ELO rating of “Full AlphaGo Zero”, which includes some randomised tree searching at play-time, against the "Raw Network" which simply predicts moves using the neural network. Without search, the network performs at roughly the level of a 3000 ELO rated player. But simply adding search to the raw network allows it to reach well above the performance of the best human players.

Once again the “Bitter Lesson” was vindicated: abandoning human-discovered knowledge, allowing the computer to learn by itself from scratch and combining this with play-time search proved to be the most effective way to scale machine intelligence to a superhuman level.
Enormous initial efforts went into avoiding search by taking advantage of human knowledge, or of the special features of the game, but all those efforts proved irrelevant, or worse, once search was applied effectively at scale… Learning by self play, and learning in general, is like search in that it enables massive computation to be brought to bear. Search and learning are the two most important classes of techniques for utilising massive amounts of computation in AI research. In computer Go, as in computer chess, researchers' initial effort was directed towards utilising human understanding (so that less search was needed) and only much later was much greater success had by embracing search and learning. - The Bitter Lesson by Rich Sutton
The Self-Taught Reasoner
Following in the footsteps of AlphaGo, the recent release of o1 from OpenAI represents yet another leap in AI reasoning capabilities, massively improving its ability to solve problems in mathematics, programming and science.
...o1 uses a chain of thought when attempting to solve a problem. Through reinforcement learning, o1 learns to hone its chain of thought and refine the strategies it uses. It learns to recognise and correct its mistakes. It learns to break down tricky steps into simpler ones. It learns to try a different approach when the current one isn’t working. - Learning to Reason with LLMs
While the exact details of how o1 was trained are not publicly available, it is pretty clear from clues released by OpenAI that it must be using a similar approach to AlphaGo. o1 is basically the application of AlphaGo-style reinforcement learning to language-based reasoning.
Reinforcement learning is actually already used to fine tune chat models’ outputs in an approach called RLHF (reinforcement learning with human feedback). In RLHF, humans rank the generated text outputs from a language model by comparing multiple answers it generated and picking the best. This data is then used to fine tune the model to steer it in the direction of producing similar answers to the ones humans prefer.

Collecting data using humans is slow and expensive, but once you have enough data, you can use it to train a reward model on these human-assigned ratings and get it to predict what grade a human annotator would assign to a new output without human assistance.
Once the reward model is trained, the process becomes much faster. You can automate the feedback loop by having the LLM generate multiple outputs to the same question, grade the outputs with the reward model (no human required!) and then fine tune the language model only on the best answer.
This process is called outcome supervision because the reward model assigns a score only to the full output of the language model. But this approach has its limitations. Sometimes the model could produce a correct answer to a question using incorrect reasoning steps. The big innovation made by o1 is in applying reinforcement learning at a more granular level by breaking down the responses to long problems into “chains-of-thought” and grading every individual step towards a problem's solution. This approach is called process supervision.

Just like with RLHF, OpenAI started by collecting data from human annotators.

But once they collected a certain amount of data, it became possible to switch to the automated approach of training a reward model and using it in a feedback loop to grade the model’s outputs without human supervision.
When we think about training a model for reasoning, one thing that immediately jumps to mind is you could have humans write out their thought process and train on that. The aha moment for me was like when we saw that if you train the model using RL to generate and own its own chain of thoughts it can do even better than having humans write chains of thought for it. That was an aha moment that you could really scale this. - Building OpenAI o1
Similar to the self-play training in AlphaGo, o1 generated thousands of chain-of-thought style answers to problems. Like AlphaGo’s random tree searches, o1 used a high temperature to increase the variance in the kinds of answers it attempted. While the model may only get the answer correct one out of a thousand times, when it succeeds, it can easily be verified using the reward model and fine-tuned back into o1 to improve its reasoning process in the future.

The final graph I will leave you with is this one from the Let’s Verify Step by Step paper by OpenAI which shows the results of best-of-N search with three different approaches. The orange line represents the performance of the process-supervised method used by o1 as compared with the outcome supervised approach, or majority voting (picking the most commonly generated output). Notice that while the other two approaches plateau after sampling 1000 solutions from the language model, the process-supervised approach seems like it has more room to scale even further. What if o1 was allowed to sample 100,000, a million, or trillions of solutions per problem? What sort of problems might it be able to solve as a result?
This graph explains the sudden focus on scaling energy production to power AI. As the Bitter Lesson has shown us, even if search seems inefficient or unintelligent, even if it requires re-opening nuclear power plants to pour energy and compute into these models, companies will be willing to put everything on the line if they believe there’s a chance it might help us solve some of humanity’s most challenging problems.
What inference cost are we willing to pay for a proof of the Riemann Hypothesis?What inference cost are we willing to pay for new life-saving drugs?
- Noam Brown in Parables on the Power of Planning in AI
I hope you enjoyed this article. If you are wondering what the implications might be of scalable machine intelligence, what the limits of o1’s approach are and how to plan your next move based on these developments, you are not alone! My next article Centaur Era Starts Now will explore those questions. Consider subscribing here or follow me on Twitter to get notified when it releases.
Thanks to algo-baker, Niccolò Zanichelli and Rammohan Sharma for their feedback on drafts of this article!
9 possible initial moves, 8 possible responses, 7 possible responses to each possible response, … etc. So 9! which equals 362,880.
https://core.ac.uk/reader/82416379?isPin=false
Great article. I'll be looking out for the next one.